[월간 챌린지] 3년차, 나에게 사이드프로젝트의 의미란
사이드프로젝트 '쿼카' 를 개발 과정을 회고해봅니다.
개발기간: 25.11 ~ 25.12
Github: https://github.com/Rory0304/quokka
배경
나는 지난 몇 년간 웹소설에 푹 빠져있었다. 읽은 웹소설만 400권이 넘었고, 그러다보니 플랫폼 별로 웹소설 읽기 기능을 구현하는 방식에 대해 살펴보게 되었다. 그 중에서 인상적이었던 것은 R사의 인용구 공유 기능이었다. 주로 SNS 플랫폼에서 유저들이 인상깊게 여긴 문장을 공유하는 용도로 사용이 되는데, 한동안 업데이트가 되지 않은 레거시 기능인 것 같았다. 사용할 수 있는 기능도 한정적이었다. 그래서 같은 스타일의 이미지들이 SNS 플랫폼에 떠도는 것을 보며 조금 더 다채롭게 만들어보고 싶다는 생각을 해본 것 같다.
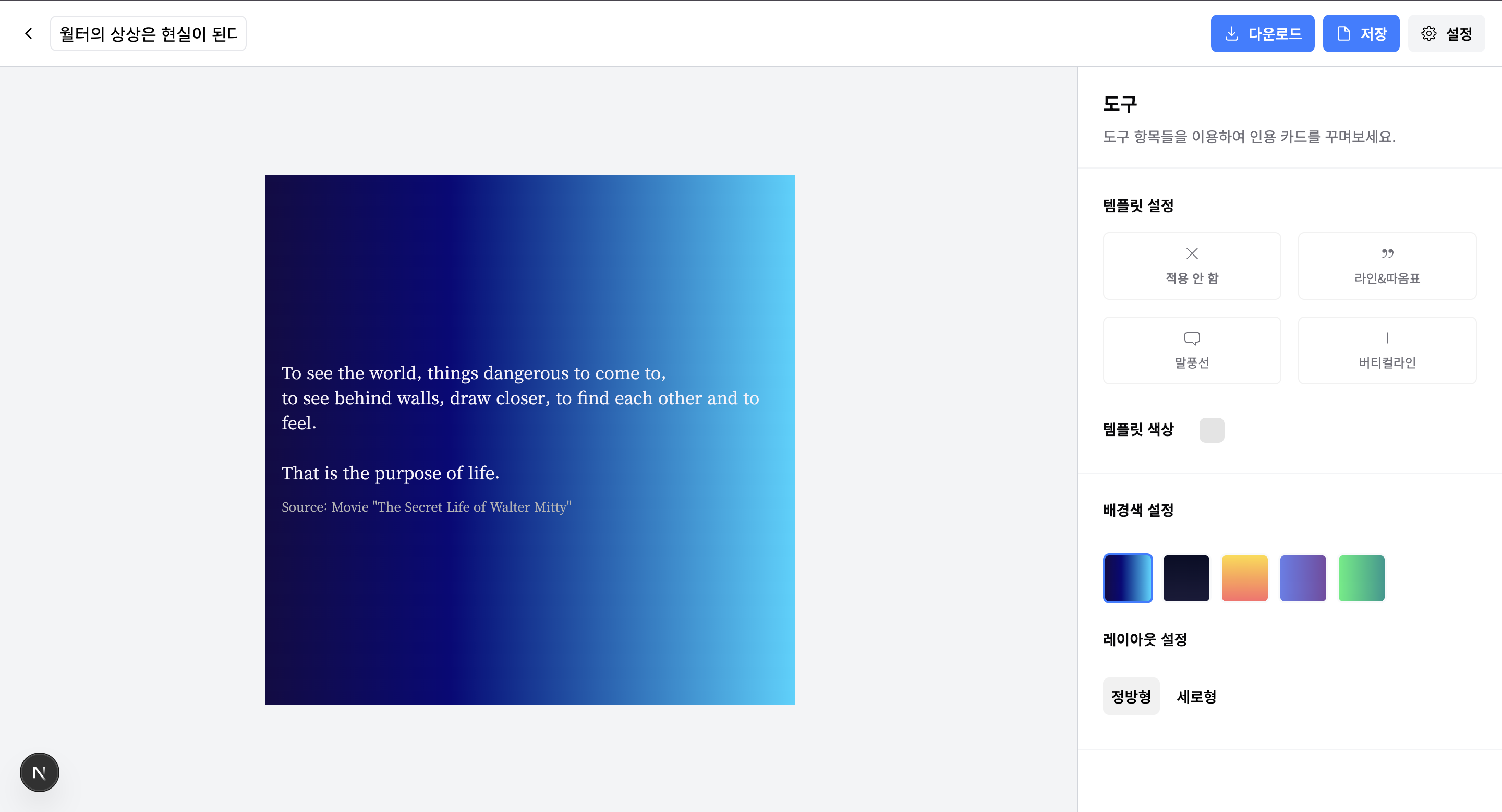
주기능은 인용구를 다양하게 꾸밀 수 있는 에디터, 서브 기능은 인용구를 공유할 수 있는 피드 기능으로 잡고 한 달간 개발을 해보기로 했다.
시작하기 전
사이드 프로젝트를 진행하면서 스스로에게 상기하고 싶었던 점은, 목적에 부합하는 결과물에 너무 치중한 나머지 과정에서의 즐거움을 놓치고 싶지 않다는 것이다. 특히 실무에서는 결과를 보여주는 것이 중요했다면, 사이드 프로젝트는 결과물을 넘어 내가 무엇을 배우고, 어떤 능력을 기르고 싶었는지 스스로 알 수 있어야 한다고 생각했다. 이번에 프로젝트를 진행하면서 배워보고 싶었던 점은 다음과 같다.
1) 개발 과정의 즐거움을 얻기
개발을 오래 하고 싶다면 성공/실패의 결과에 집중하는 것이 아니라 과정에서 배울 수 있어야 한다.
2) 내가 구현하고 싶은 기능을 만들어보기
실무에서는 기획을 잘 구현하는 것이 목적이라면, 사이드프로젝트는 나의 욕망(?)이 잠뜩 담긴 기능을 구현할 수 있다!
3) 조금이라도 합리적인 정답에 가까워질 수 있도록 개발해보기
스타트업에서 일하면서 빠르게 버그를 해결하는데 치중하다보니, 정말 최적의 정답은 무엇일지 고민하는 시간이 부족했다. 이번 사이드프로젝트로 고민하는 법을 숙련해보고 싶다.
4) AI 와 함께 개발하되, 어떻게 잘 사용할 수 있을지 고민하기
나는 코드를 작성하는 행위 자체를 좋아하지만 AI 와 함께 사용했을때 그 즐거움이 반감이 되는 경우가 있었다. 피할 수 없다면 조금 더 잘 사용할 수 있는 환경을 구축해보고 싶었다.
스택 선정
우선 기본적으로 Next.js 서버 API를 활용한 풀스택 SaaS 를 만들고 싶었다. 데이터베이스는 인증/스토리지 기능을 제공하면서 무료 플랜 이용이 가능한 Supabase 와 Prisma ORM 을 선택했다. Prisma ORM 의 경우 이번에 처음 사용해보는 스택이다. 지난번 Supabase 를 활용하면서 SQL 문을 작성하거나 직접 테이블 필드를 설정하는 번거로움이 있었는데 Prisma ORM 은 타입스크립트와 호환이 좋고 안정성이 있는 쿼리를 작성한다는 역할을 부여할 수 있어서 DB/Storage/Auth 를 관리하는 Supabase 과 역할 분리가 가능하다고 생각했다. 그 밖에 서버 데이터를 패칭하고, 캐시 관리 및 동기화 로직을 조금 더 원할하게 하기 위해 Tanstack Query 를 선택했다. 스타일링으로는 Radix UI + Tailwind 를 선택했는데, Radix UI 가 Tailwind 를 사용하면서도 접근성과 사용성을 고려한 Headless UI 라서 컴포넌트를 작성함에 있어 커스텀이 용이할 것으로 기대했다.
고민하기
다음은 프로젝트를 진행하면서 겪은 고민 과정이다. 신입 시절에 했던 고민을 3년차 시점에 다시 복기해볼 수 있었는데, 시간이 지나 녹슬게 된 지식도 있어서 새롭게 습득한 경우도 있었다. 이번 프로젝트를 진행한 덕분에 조금 더 넓은 시야로 문제를 바라볼 수 있게 된 기회가 된 것 같다.
1. 무조건 Optimistic Update 를 적용하는 것이 좋을까?
미션
데이터 리스트에서 개별 아이템을 삭제하는 기능을 구현하는 상황이다. 빠른 UX 를 위해 Optimistic update 를 적용하는 것이 좋을지 고민이 들었다.
고민해보기
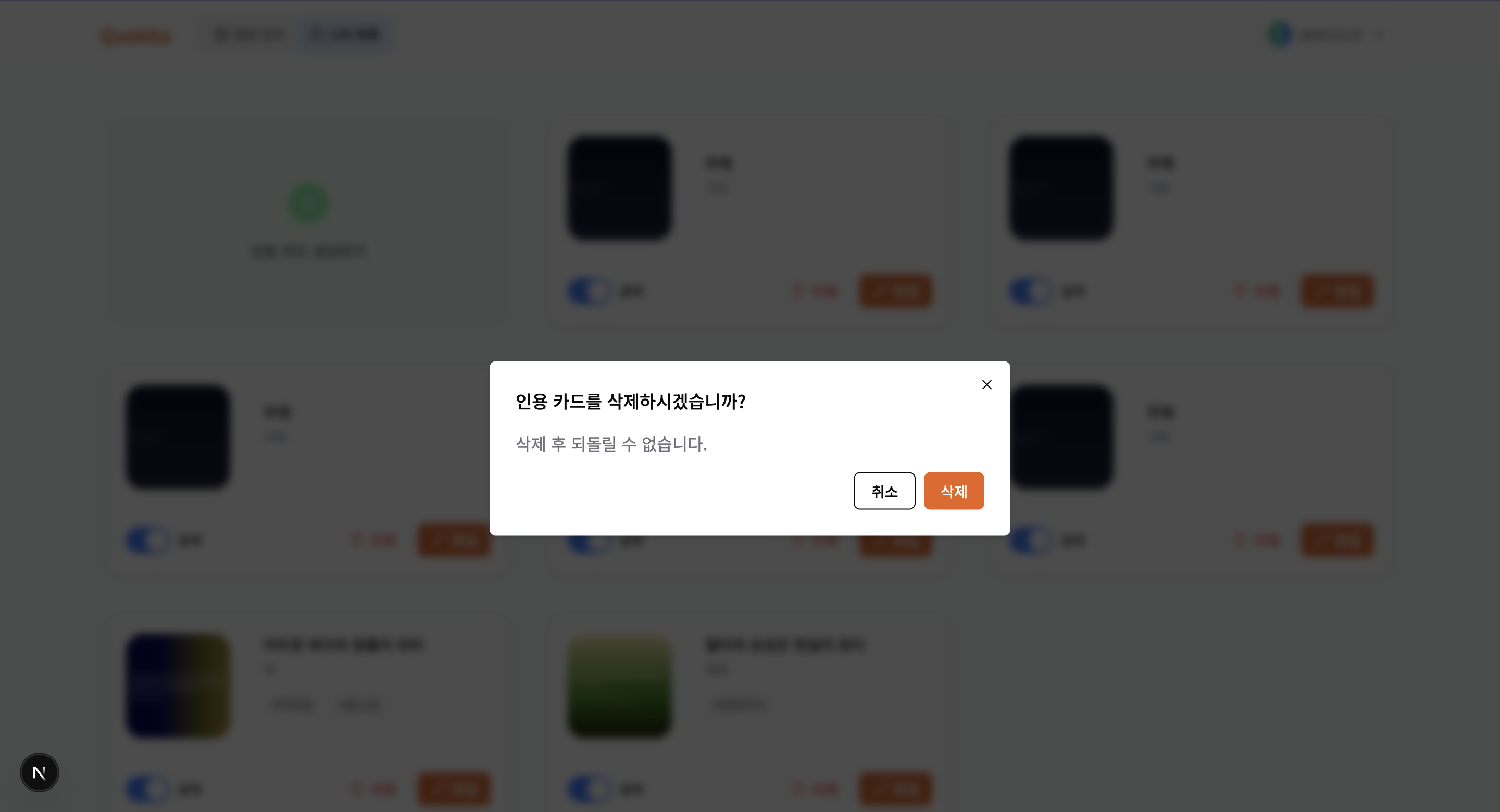
무조건 낙관적 업데이트를 사용하는 것은 옳지 않다. 낙관적 업데이트는 기본적으로 서버의 응답을 기다리지 않고 사용자의 행동을 즉시 UI 에 반영하고 싶을 때 사용한다. 예를 들어 북마크, 토글처럼 중요도가 높지 않으면서 빠른 UX 가 중요할 때 사용한다. 은행 데이터처럼 중요도가 높은 서비스에서는 사용되지 않는다. 사용자 데이터를 삭제하는 것은 중요도가 높고 주의를 요하는 작업이다. 따라서 낙관적 업데이트로 데이터를 바로 삭제를 해주는 빠른 UX를 지원하기 보다, Dialog UI 를 활용하여 사용자에게 한 번 컨펌을 받는 과정을 거친 후 삭제를 할 수 있어야 한다.
| 북마크를 토글하는 UX 는 낙관적 업데이트를 적용했다. |

| 데이터를 삭제하는 UX 는 빠른 반응성보다 정확성을 요하는 UX 이기 때문에 Dialog 단계를 추가헀다. |
2. 로직을 무조건 합치기보다는 각 역할에 맞게 분리가 가능한지 살펴본다.
미션
useEditorAction훅에서 데이터 Create, Update 로직과 함께 사용되는 이미지 업로드 mutation을 관리한다.- Update 를 진행하는 로직에서 try-catch 를 적용하여
isLoadingstate 를 정의해야 한다.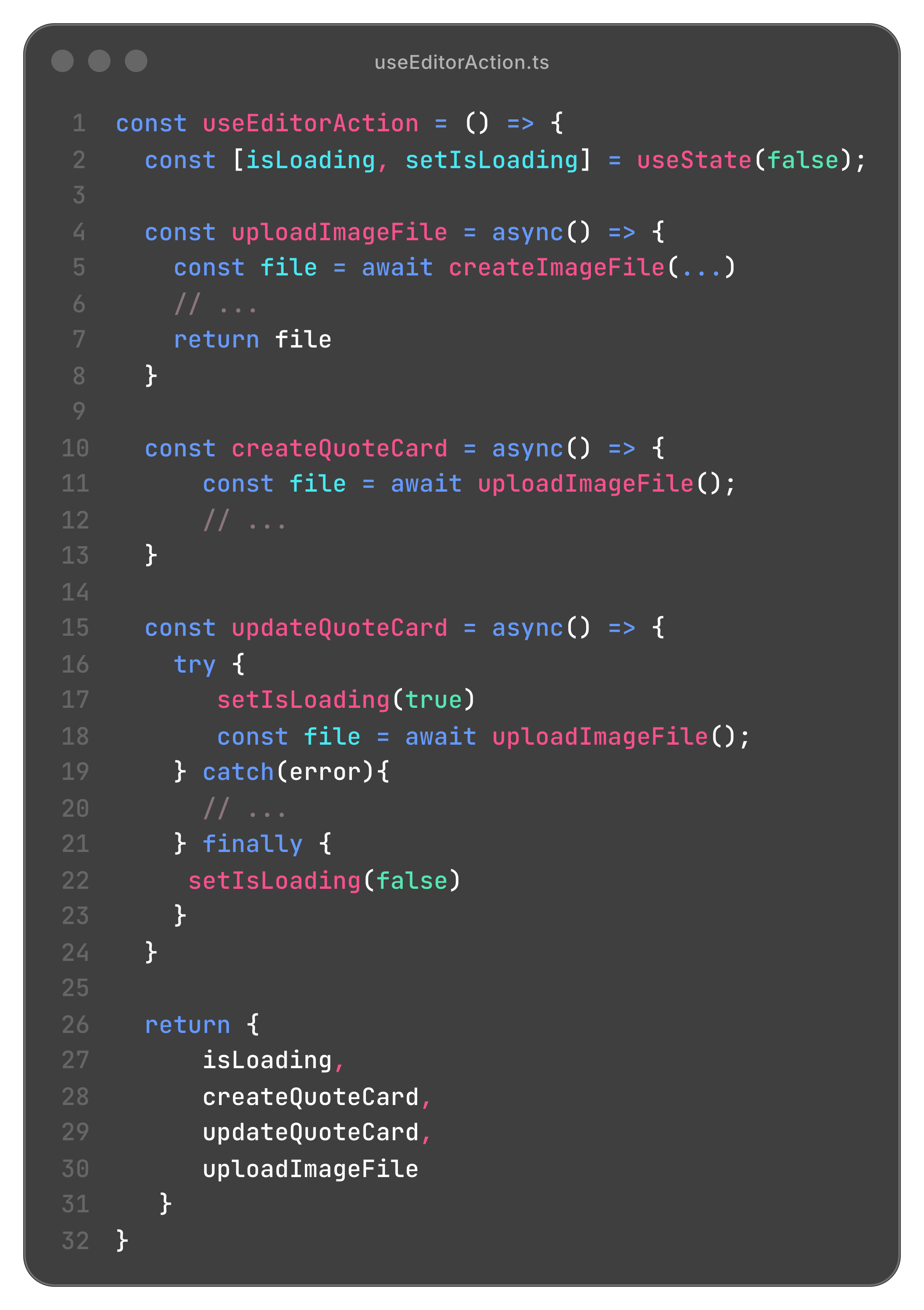
현재 문제점은 useEditorAction 에서는 관련된 모든 액션 로직을 정의하고 있기 때문에 코드를 읽을때 isLoading state 가 무엇을 관리하는지 알기 어렵다. 또한 isEditorUpdateLoading 으로 네이밍을 정의한다고 해도 Update 로직뿐만 아니라 Create, Image Upload 로직까지 훑어야 하는 문제가 있다.
고민해보기
먼저 훅이 담당하는 책임이 무제한적으로 늘어날 가능성이 있는지 살펴봐야 한다. 만약 useEditorAction 훅에서 CU 뿐만 아니라 RD 까지 다루게 된다면? 더불어 각각의 메소드에 대해 state 를 정의해야 한다면? 훅이 담당하는 역할이 비즈니스 로직이 추가됨에 따라 늘어나게 될 것이다. 하나의 기능이 담당하는 영역이 넓고, 구현이 길어질 수록 어떤 역할을 하는지 파악이 힘들어진다. 좋은 성능을 위해서는 특정한 상태 값이 업데이트되었을 때 최소한의 부분이 리렌더링 될 수 있도록 설계해야 한다.
TO-BE
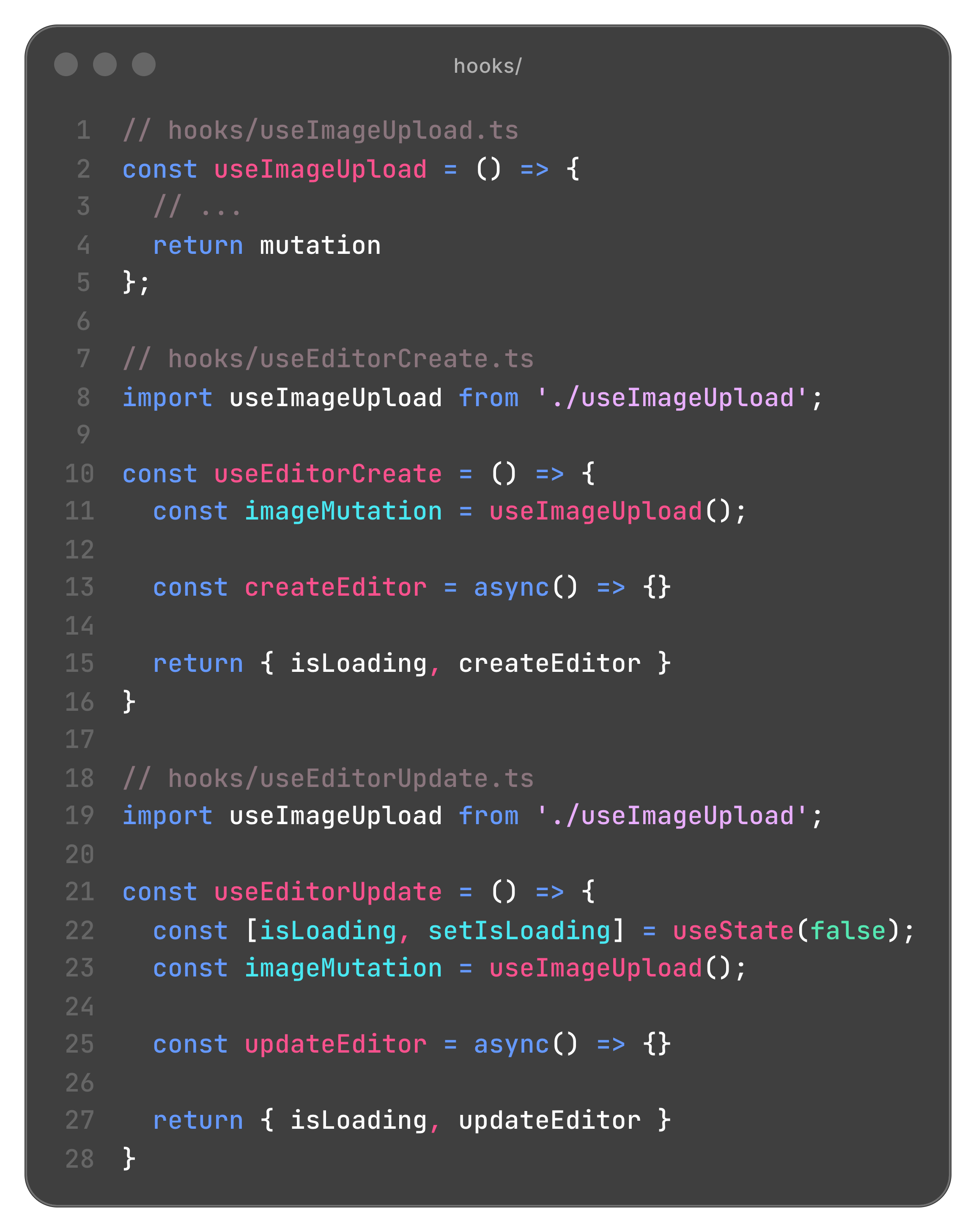
기존 useEditorAction 의 훅에서 Create/Update/Image Upload 를 책임에 따라 각각 분리한다. 이미지를 업로드하는 용도의 훅을 따로 분리하여 Create, Update 에서 임포트하여 사용할 수 있도록 한다. 또한 isLoading 과 같이 같이 실행되지 않는 코드는 따로 분리하여 실행될 수 있도록 한다.
- useImageUpload.ts: 이미지 업로드를 관리하는 훅
- useEditorCreate.ts: 에디터의 생성 액션을 관리하는 훅
- useEditorUpdate.ts: 에디터의 업데이트 액션을 관리하는 훅 < isLoading state 는 여기서 다룬다.
3. Context API 와 zustand 를 한 번에 다루는 상황에서 좋은 디렉터리 구조는 무엇일까?
디렉토리 설계에 있어 정답은 없다고 생각한다. 하지만 명확한 기준은 있어야 한다. 내가 생각하기에 디렉토리는 로직의 실행 단위를 어느 범주로 잡느냐에 대한 것이기도 하다.
예를 들어 root에 위치한 /utils 디렉토리는 페이지 전역에서 다루는 유틸을 다룰 수 있다. 하지만 /pages 하위에 속한 디렉토리(ex: /pages/example) 는 특정 page 내에서만 다루는 로직을 다룰 수 있을 것이다.
현재 페이지별 로직을 다루는 디렉토리는 /pages/A, /pages/B 로 설계가 되어 있다. 즉, A 에 대한 컨텍스트를 다룬다면 Context API 전용 디렉토리를 root 에서 분리하는 것이 아니라, /pages/A/contexts 에서 관리하는 것이 좋을 것 같다. 반면 zutand 는 전역 단위에서 실행되기 때문에 root 에서 /store/ 로 관리한다.
4. 언제 예외를 던지고(throw), 언제 예외를 처리(Exception) 할 것인가
아주 기초적인 질문이지만, 조금 더 내 생각을 명확하게 하고 싶어서 글로 작성해본다. 예를 들어, 2개 이상의 엔드포인트를 사용하는 상황에서 각 선언마다 try-catch 로 오류를 처리해야 할까? 아래의 예시를 살펴보자. main 을 호출할 경우, 과연 main 에서 오류가 잡힐까?
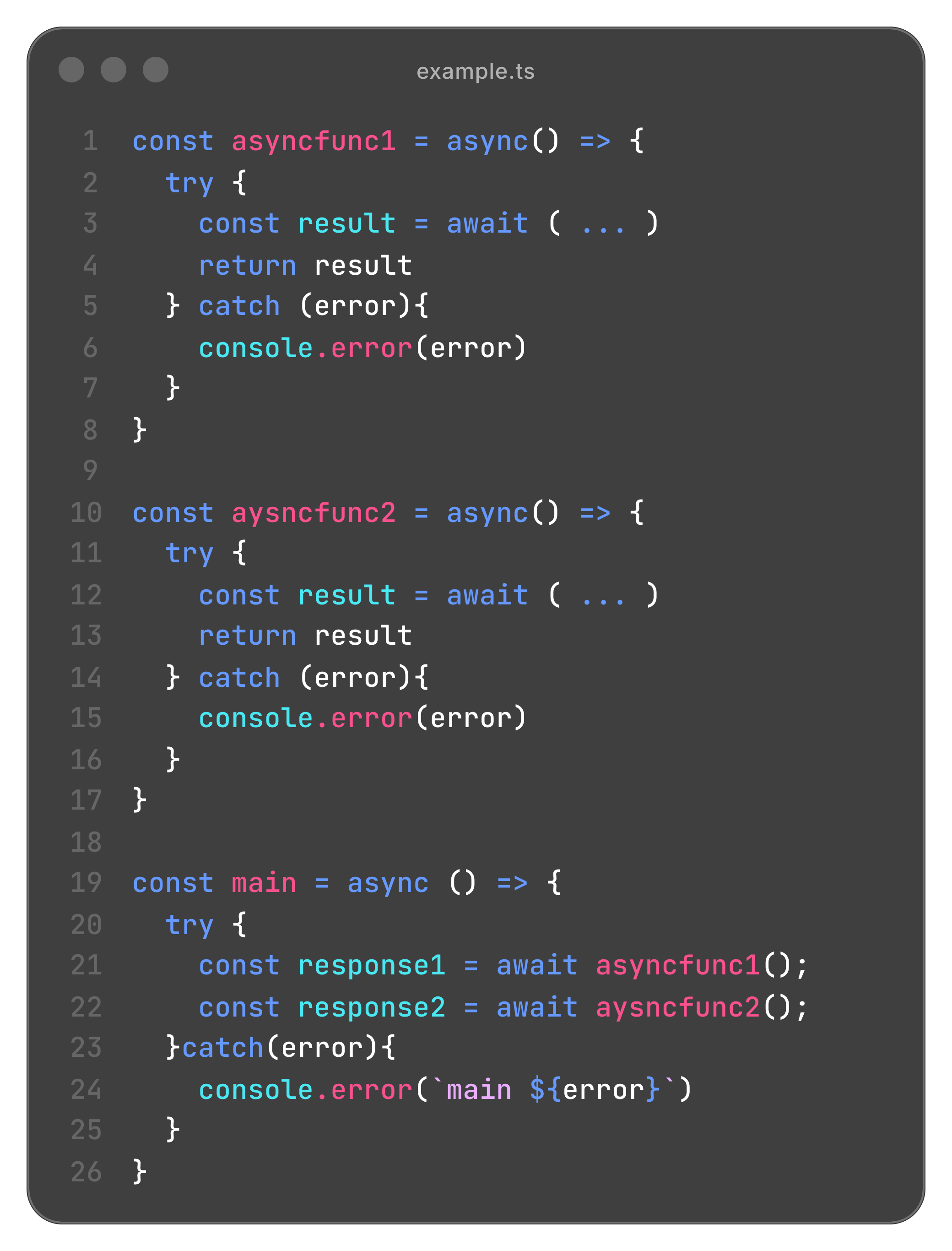
main 에서 호출 시 asyncFunc1 에서 이미 catch 문으로 오류가 잡혔기 때문에 asyncFunc1 에서 오류 처리가 먼저 실행된다. asyncfunc2 도 마찬가지다. 그래서 결과적으로 main 에서는 오류가 잡히지 않는다.
asyncfunc이 순수한 API 호출 로직이라서 다른 컴포넌트에서도 임포트해서 사용한다고 했을때는 상황이 상당히 애매해진다. try-catch 로 오류를 잡을 경우 실제 사용부(main) 에서는 실질적인 오류 처리(fallback) 을 할 수 없게 되기 때문이다. 즉, 위 코드의 문제점은 try-catch 문으로 인해 정상 동작과 오류 처리 동작이 섞인다는 점에 있다. 그래서 예외를 던지는(throw) 시점은 현재 함수가 문제를 해결할 수 없는지를 확인해야 하며, 예외를 처리하는(catch) 시점은 오류 Fallback 을 처리할 수 있는지를 확인해야 한다.
When your code can’t recover from an exception, don’t catch that exception. Enable methods further up the call stack to recover if possible.
코드가 예외로부터 복구할 수 없는 경우, 해당 예외를 잡지 마세요. 가능하다면 호출 스택의 상위 메서드가 복구할 수 있도록 하세요.
Ref) https://learn.microsoft.com/en-us/dotnet/standard/exceptions/best-practices-for-exceptions
.png)
5. 비동기를 조금 더 우아하게 다루는 방법
잠시 토스의 세미나 영상을 보자. 내가 여기서 배운점을 요약하면 다음과 같다.
TL;DR
1) async-await 의 장점은 모든 에러 처리는 외부에 위임한다는 것에 있다.
2) 좋은 코드의 특징은 다음과 같다.
- 성공, 실패 경우를 분리해 처리할 수 있다
- 함수에 성공하는 케이스만 작성하고, 외부에서 에러를 캐치하여 처리한다.
- 비즈니스 로직을 한 눈에 파악할 수 있다
3) 어려운 코드의 특징은 다음과 같다.
- 실패, 성공 경우가 서로 섞여서 처리된다
- 비즈니스 로직을 파악하기 힘들다
4) 보통 react-query 의 경우, data, error 의 값을 반환함에 따라 컴포넌트에서 로딩과 에러를 동시에 수행했다.
- 성공하는 경우와 실패하는 경우가 섞여서 처리된다
- 실패하는 경우에 대한 처리를 외부에 위임하기 어렵다
- 이를 우아하게 처리할 수 있는 방법으로 Suspense + Error Boundary 가 있다.
AsyncBoundary 구현하기
토스 세미나에서 배운 것처럼 비동기를 선언적으로 다루면 조금 더 코드가 깔끔해질 수 있을 것 같았다. 그래서 토스 라이브러리 코드를 살펴보면서 Suspense + Error Boundary 의 조합인 AsyncBoundary 를 사용하고 있음을 확인할 수 있었고 이를 직접 구현해서 적용해보기로 했다.
먼저 ErrorBoundary는 클래스 컴포넌트로 구현해야 한다. 왜냐하면 내부에서 사용되는 라이프사이클 메소드가 클래스 컴포넌트에서만 잡아내기 때문이다. getDerivedStateFromError 는 오류가 발생하면 상태를 업데이트하는 메소드다. componentDidCatch는 오류를 로깅하고 추가 처리하는 메소드다.
ErrorBoundary 는 errorFallback 을 인자로 받아 오류가 발생할 경우 보여주는 fallback 을 실행하며 오류로 부터 데이터 갱신을 할 수 있는 reset 을 실행한다. 이때 react-query 를 사용할 경우 QueryErrorResetBoundary 에서 전달하는 reset을 통해 쿼리를 다시 패치할 수 있도록 선언적 방식을 제공한다.
ErrorBoundary
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
import { Component, ComponentType, ErrorInfo, ReactNode } from "react";
interface ErrorBoundaryProps {
errorFallback: ({ reset }: { reset: () => void }) => React.ReactNode;
resetQuery: () => void;
children: ReactNode;
}
interface ErrorBoundaryState {
hasError: boolean;
error: Error | null;
}
export class ErrorBoundary extends Component<
ErrorBoundaryProps,
ErrorBoundaryState
> {
constructor(props: ErrorBoundaryProps) {
super(props);
this.state = { hasError: false, error: null };
this.reset = this.reset.bind(this);
}
/** 오류 발생 시 상태값을 업데이트함 */
static getDerivedStateFromError(error: Error): ErrorBoundaryState {
return { hasError: true, error };
}
/** 에러 상태 초기화 */
reset(): void {
this.props.resetQuery();
this.setState({
hasError: false,
error: null,
});
}
/** 오류 로깅 */
componentDidCatch(error: Error, errorInfo: ErrorInfo) {
console.error("ErrorBoundary caught an error:", error, errorInfo);
}
render() {
const { errorFallback } = this.props;
if (this.state.hasError) {
return errorFallback({
reset: this.reset,
});
}
return this.props.children;
}
}
SSRSafeSuspense
Suspense는 서버 사이드 렌더링 환경에서 지원하지 않지만, 서버에서 렌더링될때 Suspense 를 읽기 때문에 오류가 발생할 수 있다.
1
Uncaught Error: Switched to client rendering because the server rendering errored
따라서 서버사이드 환경에서 전달받은 fallback 이 실행 가능한 환경인지를 살펴보고 서버사이드 환경이라면 Suspense 를 제외한 fallback 을 실행한다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
import { useMounted } from "@/hooks/common/useMounted";
import { ComponentProps, Suspense } from "react";
export default function SSRSafeSuspense(
props: ComponentProps<typeof Suspense>
) {
const isMounted = useMounted();
if (isMounted) {
return <Suspense {...props} />;
}
return <>{props.fallback}</>;
}
사용부
이제 react-query 로 부터 isLoading, error 체크를 하는 과정이 없이도 AsyncBoundary 로만 감싸면 된다!
1
2
3
4
5
6
<AsyncBoundary
pendingFallback={pendingFallback}
errorFallback={({ reset }) => (<ErrorAlert {...} onReset={reset} />)}
>
<Content />
</AsyncBoundary>
6. 리스트 페이지네이션 상황에서 아이템 상태값을 확인하는 API 는 어떻게 설계해야 할까?
상황
피드의 페이지네이션을 하면서 북마크가 활성화 되었는지 확인해야 한다. 총 2가지 방법을 생각해봤는데 어떤 방법이 좋을지 파악해보려 한다.
1) 클라이언트 사이드에서 사용자가 북마크한 아이템을 Set 형태로 가져와서 Item 스크롤 할때마다 Set 에 담겼는지를 살펴본다.
- 페이지네이션 [GET]
/api/items?page=1 - 북마크 상태 조회 [GET]
/api/bookmarks/check?itemsIds=1,2,3,4
2) 페이지네이션 API 응답값에 isBookmarked 상태값을 포함한다.
- 북마크 테이블의 값을 서브쿼리로 가져온다.
고민해보기
2가지 방법 모두 해결 방안이 될 수 있으나 각각 트레이드오프가 있는 것 같았다. 첫 번째 방법은 메인 쿼리로만 진행하기 때문에 페이지네이션 조회 쿼리가 조금 더 빠를 수 있다. 하지만 페이지네이션을 하고 북마크 상태를 조회하는 총 2번의 API 호출 과정이 필요하다. UI 상에서 깜빡임이나 스크롤이 길어질 수록 네트워크 트래픽을 피할 수 없을 것이다.
두 번째 방법은 한 번의 페이지네이션 쿼리로 데이터를 조회 가능하지만 서브쿼리의 비용이 발생한다. 또, 북마크 테이블이 크면 클수록 성능 영향이 있을 수 있다. 이를 최적화하기 위해서는 bookmarkId 와 userid 칼럼에 고유 id 를 부여하는 인덱싱 방법을 적용하거나, 캐싱을 활용하여 메모리 캐시에 조회결과를 저장하고 동일한 쿼리가 반복될 때 데이터베이스 조회를 줄이는 방법이 있는 것 같았다.
내가 추출해야 할 칼럼은 단순히 북마크의 활성화 여부였기 대문에 간결한 요청이였으므로 서브 쿼리 방식을 적용했다. Prisma 를 사용하고 있기 때문에 JOIN 처럼 동작하는(실제로는 SELECT가 2번 실행됨) include + select 구문을 활용하여 _count 를 구성했고 이를 기반으로 북마크 상태를 체크했다.
1
_count: { select: { bookmarks: { where: { userId } } } } // postId 에 해당하는 boomark 에 userId 가 포함되어 있는지 확인
왜 Prisma 는 JOIN 구문이 없을까?
앞서 보았듯, Prisma 에서는 include + select 옵션을 통해 쿼리 응답에 join 되는 테이블의 일부 필드를 보여줄 수 있다. 하지만 실제로 prisma 는 JOIN 이 아니라 Select 쿼리를 2번 보낸다. 즉 실제 JOIN 동작은 존재하지 않지만 JOIN 처럼 보이도록 하는 작업을 할 수 있는 것이다.
따라서 Prisma 는 JOIN 의 부재로 성능 이슈가 존재한다. 크리티컬한 쿼리에 한하여 JOIN 을 RAW Query(SQL) 로 작성할 수 있도록 지원은 하고 있다. 그런데 왜 JOIN 이 없는 것일까? 출처에 따라 요약하면 다음과 같다.
- Prisma 의 궁극적인 목표는 좋은 ORM 이 아니다.
- Prisma 는 여러 데이터베이스가 동시에 사용되는 개발 환경을 상정하고 만들어졌다.
- 즉 RDBMS + NoSQL 과 같은 다양한 데이터베이스가 사용될 것을 고려한 시스템이다.
- 이를 실현하려면 많은 DB 를 Prisma 와 연결할 수 있어야 한다. 그래서 Prisma 의 백엔드는 각 데이터베이스에 맞는 SQL 을 생성하고, 이를 전달하는 커넥터와 이 밖의 모든 작업을 담당하는 코어 엔진으로 구성했다.
- 즉 코어와 커넥터가 효율적으로 결합된 ORM 이 아니라, ‘커넥터의 에코시스템’에 가깝다.
- 많은 데이터베이스에는 JOIN 과 같은 서브쿼리 기능이 존재하지 않는다. 그렇기 때문에 Prisma는 공통적인 파싱 로직만을 적용한다.
7. 언젠가는 배워야 할 테스트코드
이번에 테스트코드를 새롭게 도입해봤다. 이유는 이전 회사들은 새롭게 스택을 시도하고 도입하는 것을 지양하는 분위기(ex: 그 시간에 기능 하나라도 더 추가하자) 였고 어쩔 수 없이 수기로 테스트를 해야 했다. 다시 생각해보면 내가 테스팅 툴에 조금이라도 익숙했다면 이 과정을 줄여서 오류를 방지할 수 있었을텐데 라는 아쉬움이 남아서 다음 회사에 가게된다면 테스팅 툴을 조금이라도 숙지해서 가고 싶었다. 테스팅 툴로는 Vitest 와 React Testing Library, Cypress 를 선택했다.
모든 로직에 대해서 테스팅 케이스를 작성하기에는 공수가 든다. 스타트업같은 현업에서도 빠르게 퍼블리싱하는 것이 중요하다면 테스트 케이스를 작성하는 것조차 불필요한 비용으로 여겨질 수 있다. 그래서 무엇을 테스트해야 할지 우선순위를 정해야 한다. 예를 들면, 서비스에서 가장 중요한 절대적인 로직이나 에러나 예외케이스가 발생할 수 있는 확률이 있는 로직들이 그 예시가 될 것이다. 이번에 내가 UI 단위 테스트코드를 작성한 컴포넌트는 LoginTooltip 과 ContentEditable 컴포넌트다.
1) LoginTooltip
로그인 되지 않은 사용자가 예기치못한 오류를 보는 것을 방지하기 위해 사용되는 조건부 컴포넌트로, 대부분의 페이지에서 공통적으로 사용되기 때문에 테스트를 추가하면 좋을 것 같았다.
- 사용자가 로그인 하지 않았을 경우 > Tooltip 컴포넌트를 display + hover 전/후에 따른 텍스트 렌더링
- 사용자가 로그인 했을 경우 > Tooltip 컴포넌트를 hide + children 만 렌더링
2) ContentEditable
에디터에서 사용되는 텍스트 입력 전용 컴포넌트로 텍스트의 비정상 입력(이모지 입력, 특수문자, XSS 공격 대비) 에 대한 테스트가 필요했다.
- 순수 텍스트의 내용이 보여져야 함
- 특수 문자의 내용이 보여져야 함
- 공백인 상태에서
<br>태그를 렌더링하지 않아야 함 - XSS 공격에 방지하여 sanitized 된 결과를 보여주어야 함
다행히 테스트코드를 작성하는 과정에서 라이브러리 내부에서 dangerouslysetinnerhtml 에 대한 대비가 안 되어 있는 것을 발견했고 따로 Dompurify 를 이용하여 sanitize 하는 과정을 거쳤다. 테스트코드에 XSS 공격 예시로 <img src='x' onerror='alert("공격")'> 를 의도적으로 작성했을 때 <img src="x"> 로 잘 필터링되는 것을 확인할 수 있었다.
3) E2E 테스트 진행하기
E2E 테스트의 목적은 사용자의 시나리오를 모방해 사용자가 개발한 시스템을 버그 없이 작동할 수 있는지에 대한 검증을 하기 위함이다. 대표적으로 Cypress와 Playwrite 가 있는데, 사이드프로젝트에서는 TS 를 기반으로 한 단순한 E2E 테스트가 주 목적이었기 때문에, JS 외 언어를 지원하고/다중탭 테스트/API 통합 테스트를 지원하는 Playwrite 가 현 프로젝트 규모에서는 방대하게 느껴졌다. 그래서 Cypress 를 선택하여 E2E 테스트를 진행해보았다. 주요 기능인 에디터의 사용에 대해서 오류가 없는지 확인하는 절차로 진행했다.
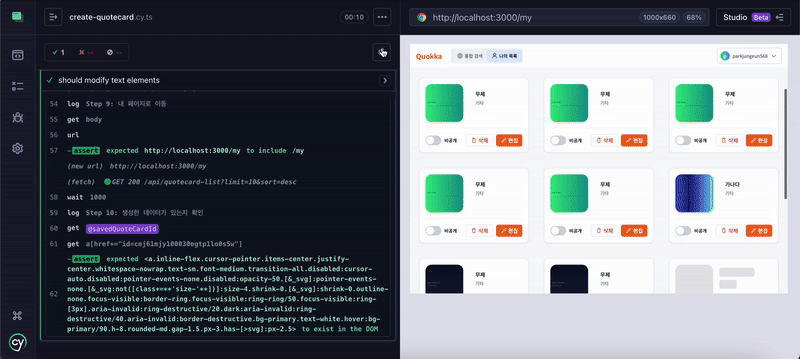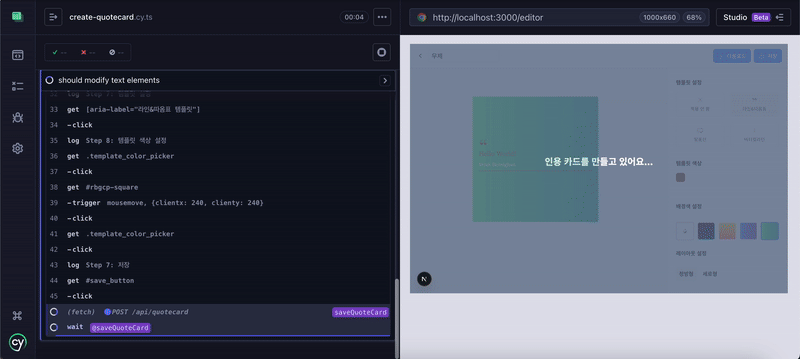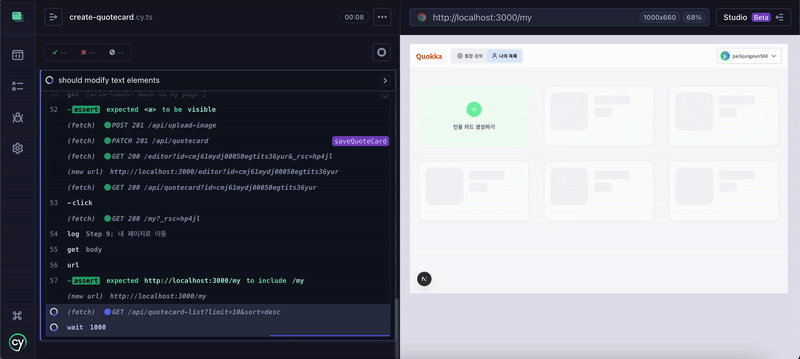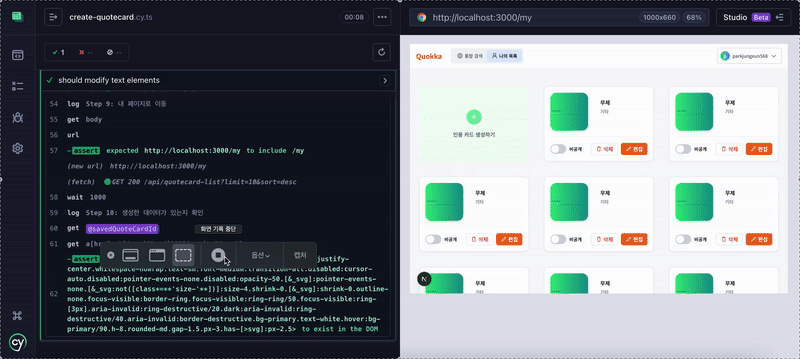
| Flow) 로그인 -> 에디터 이동 -> 인용 카드 편집 -> 저장 -> 인용 카드 설정 -> 저장 -> 나가기 -> 마이페이지 -> 결과 확인 |
8. AI의 사용에 대해
IDE 로는 Cursor 를 사용하고, 자세한 질문에 대해서는 Claude 를 사용했다. 나는 객관적인 실력면에서는 아직 멀었다(;;) 는 생각이라 AI 의 자동완성 기능에 무조건 의지하면 안 될 것 같다는 생각이 들었다. 그래서 Golden Rule 에 ‘코드를 직접 수정하지 말고, 아이디에이션을 먼저 제안할 것’ 을 규칙으로 삼았다.
(ME) 먼저 스스로 고민해보고 -> (AI) 더 좋은 방식 제안을 받음 > (ME) 다시 고민해서 작성 > (AI) 코드 검수 방식으로 진행했는데, 이 방식이 나에게 훨씬 좋았다.
그 밖에 다른 시니어들이 사용하고 있는 룰을 참고해서 나에게도 맞춰서 적용해보았다. 예를 들면 다음과 같은 Rule 이다.
1) 코드를 읽는 과정에서 Eye Movement 를 줄일 수 있는 방안을 먼저 적용한다.
- if-elseif 의 중첩의 사용을 지양하고, inline switch 처럼 시각화가 가능한 코드를 사용한다.
- 단순한 로직은 무조건 분리하는 것이 아니라 관련된 로직에 colocate 한다.
2) Golden Rule
- 오버엔지니어링을 하지 않고, 불필요한 복잡도를 줄일 수 있는 방안을 생각한다.
- 요청 사항이 애매하거나 완전하지 않으면 먼저 사용자에게 확인을 받고 코드 개선을 진행한다.
- 모든 코드를 처음부터 구현하려고 하지 않는다. Stable 하고 자주 적용되는 오픈소스 라이브러리 먼저 살펴본다.
- 유저가 수정하라는 명령을 내리기 전까지는 코드를 직접적으로 수정하지 않는다. 먼저 수도 코드같은 개선 방안을 제안한다.
마무리
화면 UI
1) 홈 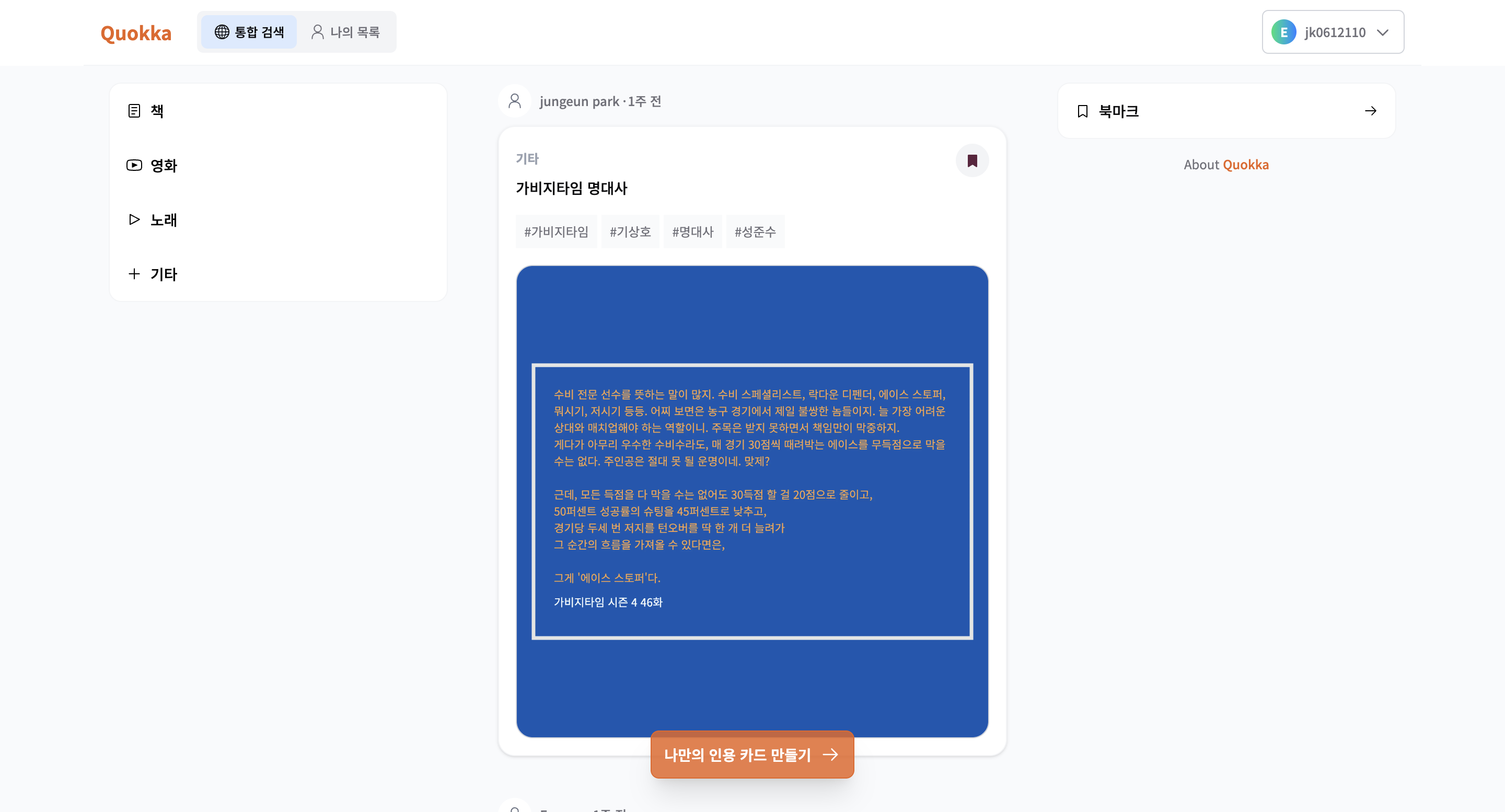
2) 에디터 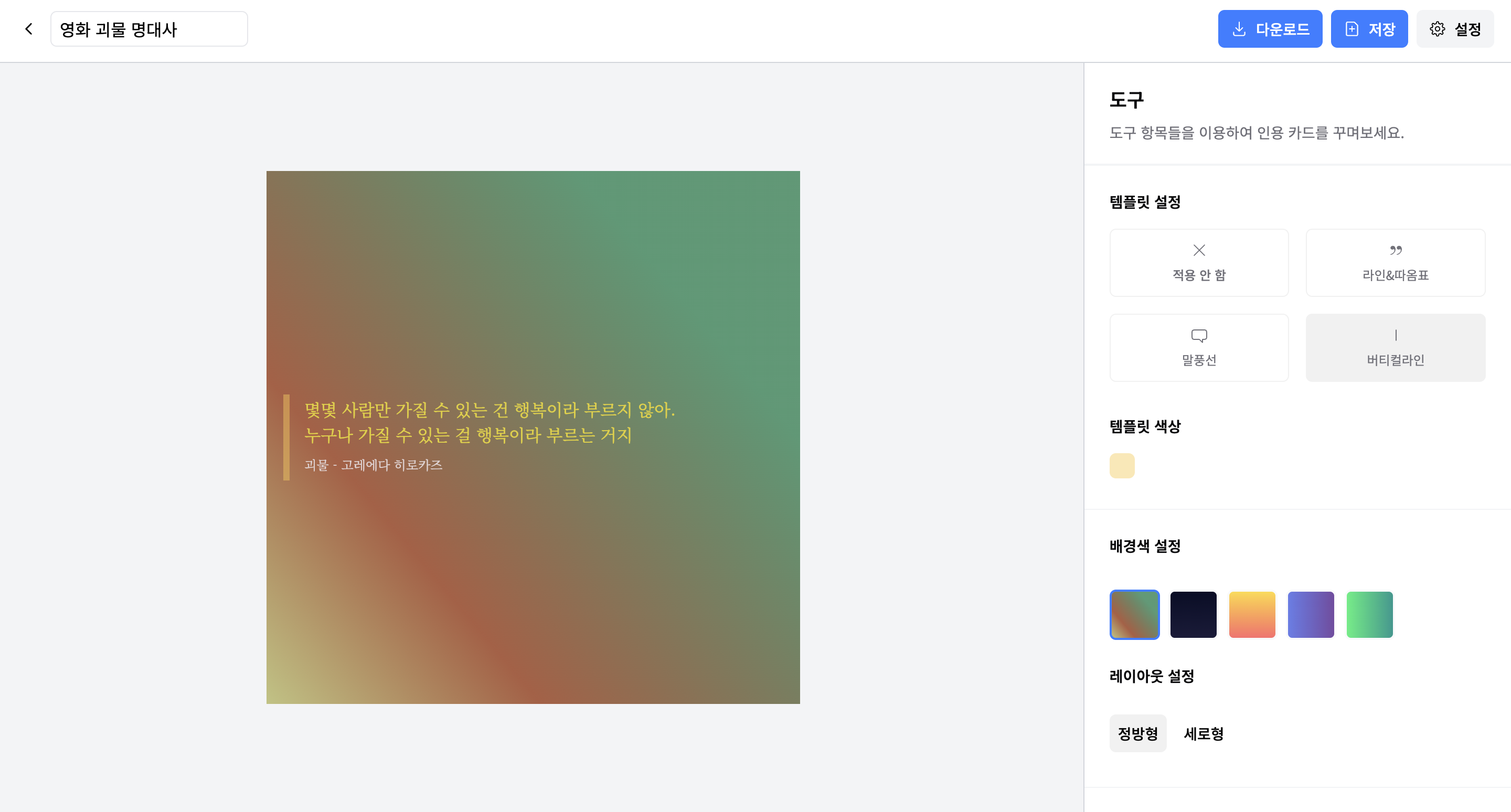
3) 에디터 설정 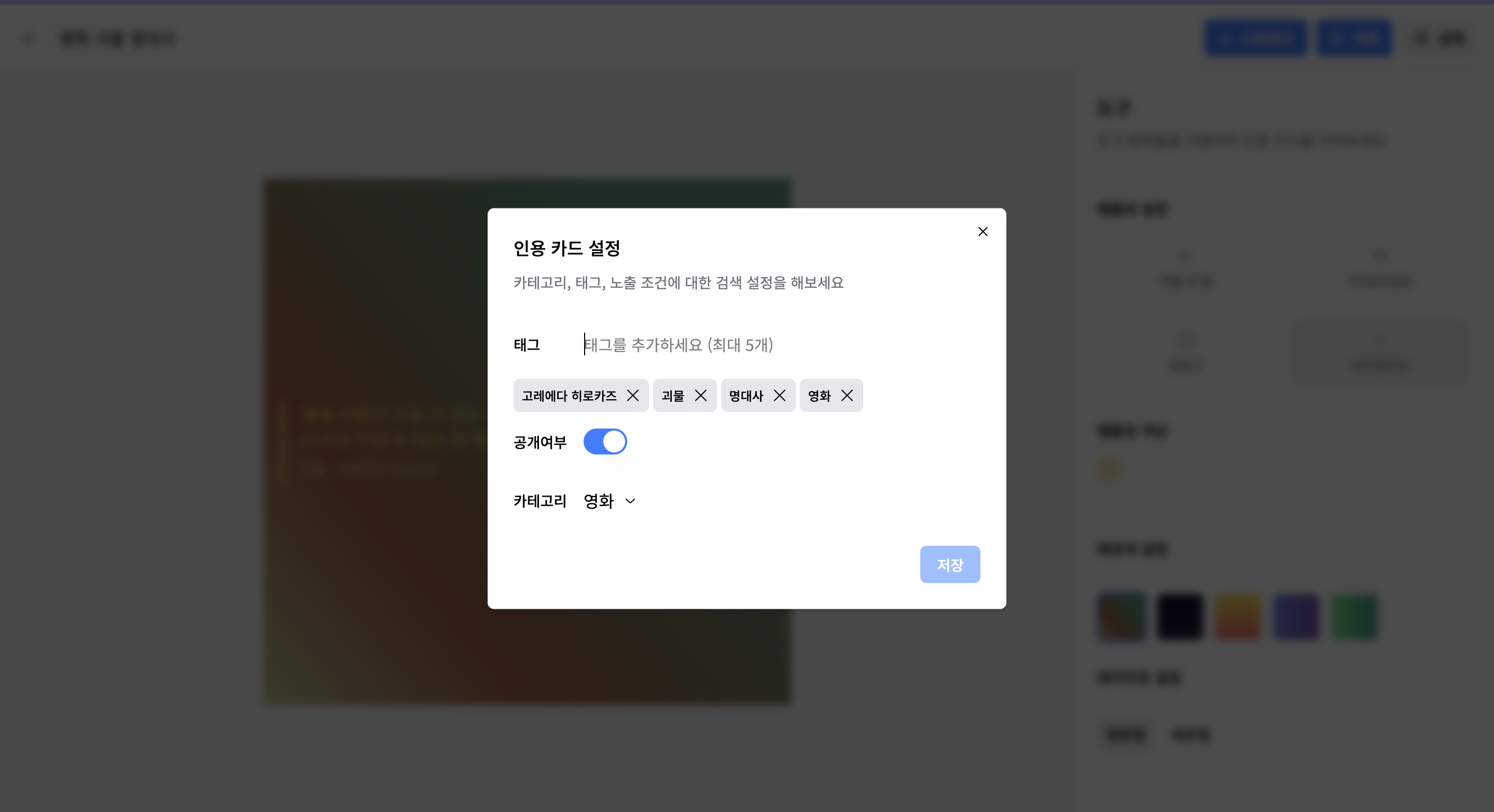
4) 마이페이지 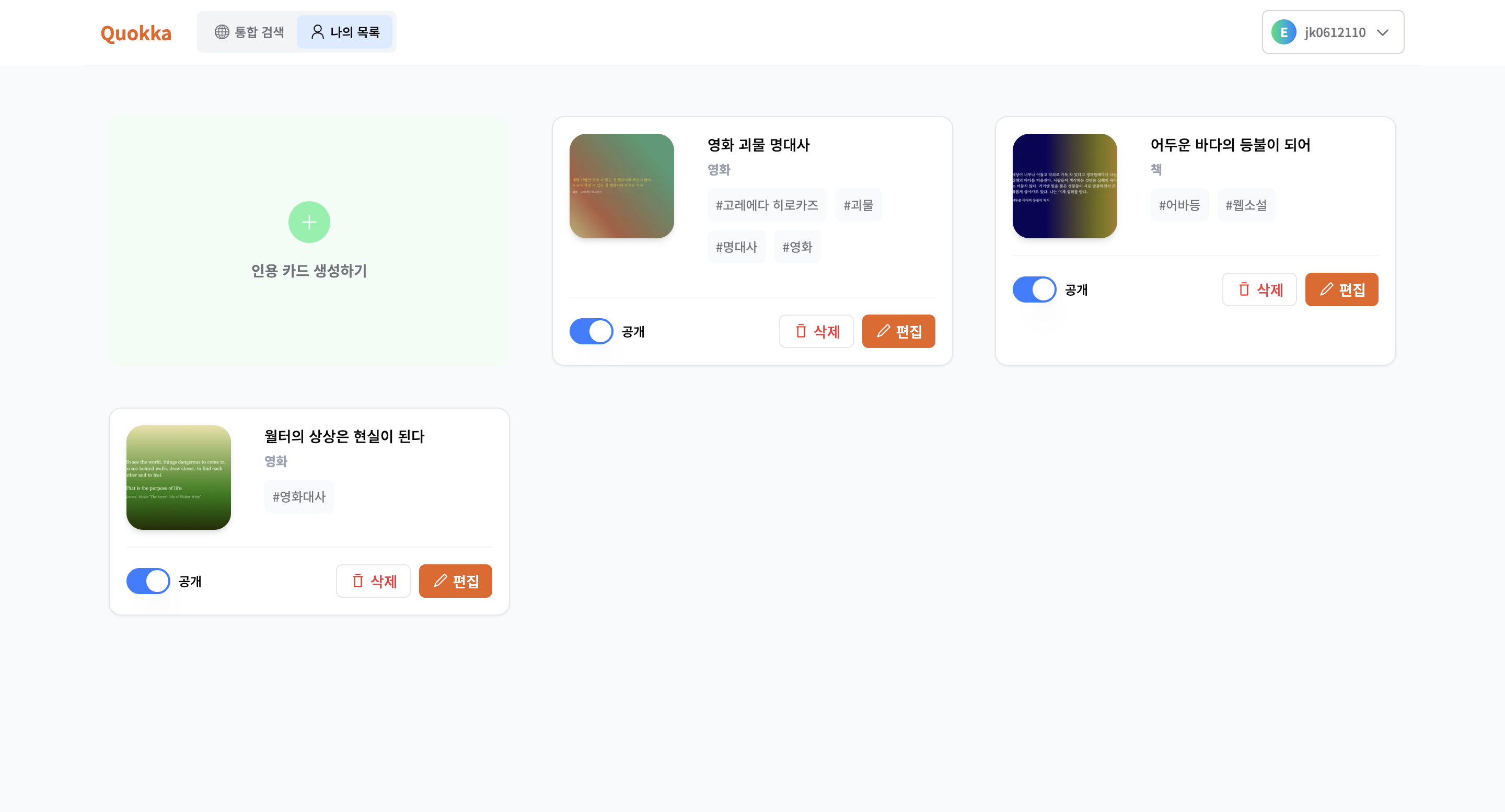
5) 북마크 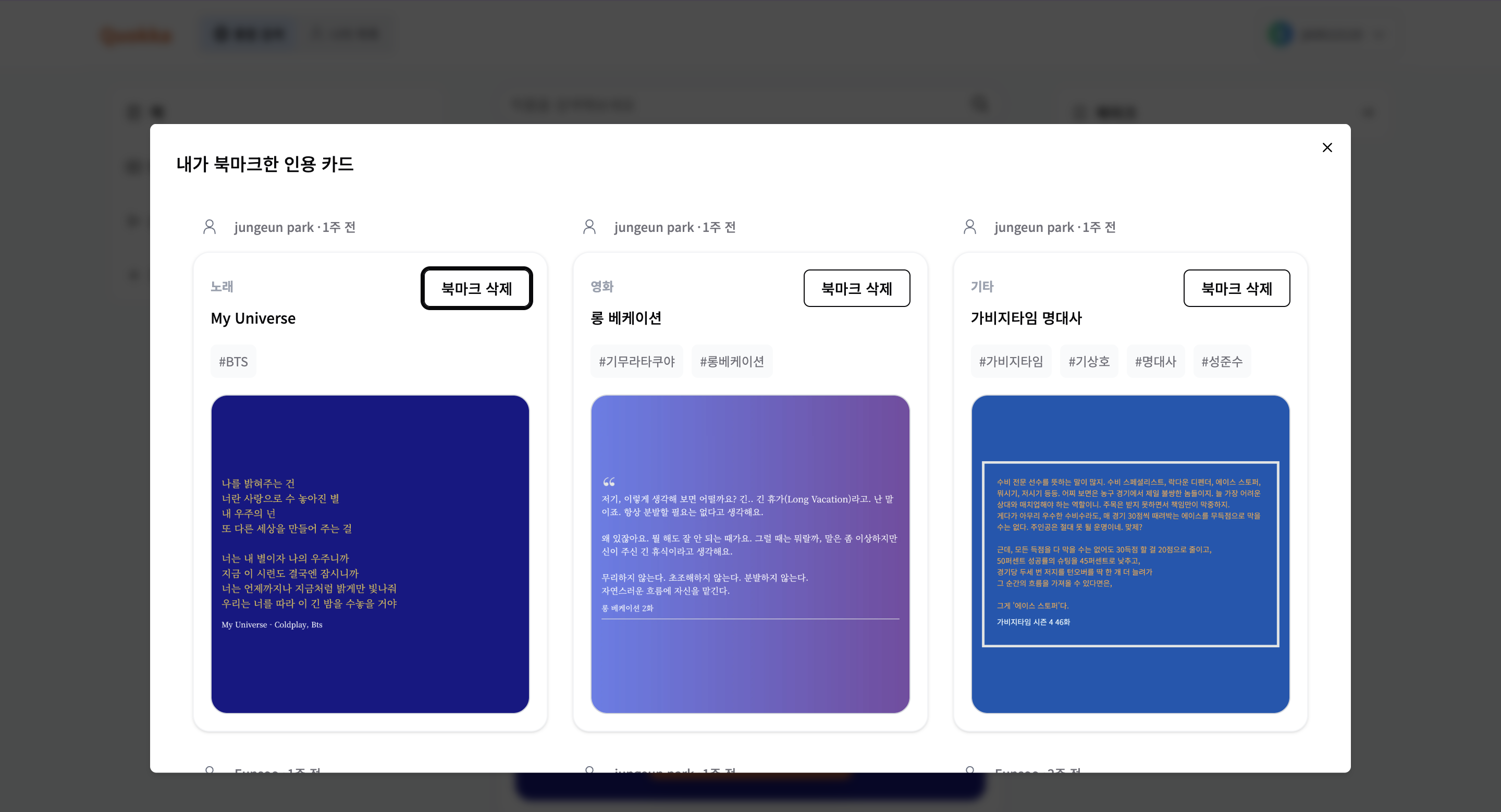
배운점
1) 기술적으로 뛰어난 것보다, 필요한 고민을 하는 것
비동기를 편리하게 다루는 방법이 무엇일지, 왜 무조건 전역 상태를 도입하면 안 되는지 등 무조건 좋다고 하는 기술을 선택을 하기보다는 타당한 이유를 찾기 위해 노력했다. 이런 고민의 과정을 통해 관성적으로 따르게된 코드 습관을 고칠 수 있었고, 속도가 빠른 조직에 가게 되더라도 이런 고민의 과정을 놓치지 말아야겠다는 나름의 다짐을 할 수 있었다.
또한 시니어님이 진행하는 사이드 프로젝트의 결과물을 보면서 어떤 디자인이 사용자에게 좋은 UX 일지 고민할 수도 있었다. 예를 들어, 보통 검색 결과를 만든다고 하면 새로운 검색 결과 페이지를 만드는 것이 태반이다. 하지만 시니어분은 검색 결과 모달을 새롭게 보여주고 페이지를 새롭게 만드는 공수를 덜어서 프로젝트의 일정과 산출 기준을 충족했다. 익숙한 UI 가 정답은 아니며 상황에 따라 새롭게 만드는 것이 더 좋은 UI를 만드는 기회가 될 수 있다는 것을 배웠다.
2) 처음부터 완벽함을 추구하지 않는다.
사실 기술적으로도, 미감적으로도 뛰어난 프로젝트가 많은 상황에서 내가 사이드프로젝트를 하는 것이 어떤 의미가 있을지, 지금보다 더 욕심을 부려도 되지 않을까 싶기도 했다. 하지만 나는 이번이 끝이 아니라 프로젝트를 계속 유지보수하고 퀄리티를 높여갈 생각이고 기회가 된다면 노마드코더에도 소개해보고 싶다. 그러기 위해서는 처음부터 완벽하려고 하기보다는 먼저 동작하는 주기능과 서브기능에 집중하여 1차적인 결과물을 만드는 것이 우선이었다. 시간은 있으니 점진적으로 개선한다는 현실적인 접근법을 택하는 것을 배웠다.