Clean Architecture 기본 개념 살펴보기
너도 할 수 있어, 클린 아키텍처
들어가며
📌 아키텍처에 대한 지식이 전무하기 때문에, 많은 블로그 글들을 읽었습니다.
이 포스팅은 참고한 글들을 학습 용도로 재구성한 글임을 밝힙니다.
참고한 원문 출처의 경우 하나씩 링크를 걸어두었으며, 모든 출처 리스트는 아래 정보를 참고해주세요.
원문 출처
- [Android] 요즘 핫한 Clean Architecture 왜 쓰는 거야?
- [한글 번역] Clean Architecture : Part 2 — The Clean Architecture
- (번역) Clean Architecture on Frontend
- [OOP] 객체 지향 5원칙(SOLID)-의존성 역전 원칙 DIP(Dependency Inversion Principle)
- [Android] 요즘 핫한 Clean Architecture 왜 쓰는 거야?
- Learn to build a Hexagonal Architecture Micro Service
- 왜 Android 신규 프로젝트는 클린 아키텍처를 도입하였는가
- [NHN FORWARD 22] 클린 아키텍처 애매한 부분 정해 드립니다.
- 주니어 개발자의 클린 아키텍처 맛보기
- 클린 아키텍처 보충 1 — 포트와 어댑터, 의존성 규칙
- 프로젝트에 새로운 아키텍처 적용하기
참고하면 좋을 강의
React with clean architecture 소스코드
클린 아키텍처
소프트웨어는 ‘기능’과 ‘구조’ 라는 두 가지 가치가 존재하며, 로버트 C.마틴은 당장 작동하는 ‘기능’보다는 소프트웨어를 유연하게 유지시키는 ‘구조’가 중요하다고 말한다.
소프트웨어가 가진 본연의 목적을 추구하려면 소프트웨어는 반드시 ‘부드러워’야 한다. 다시 말해 변경하기 쉬워야 한다. 이해관계자가 기능에 대한 생각을 바꾸면, 이러한 변경사항을 쉽게 적용할 수 있어야 한다.
-로버트 C. 마틴, 클린 아키텍처
여기서 ‘아키텍처’는 시스템의 형태이다. 시스템을 여러 컴포넌트로 분리/배치/의사소통하는 방식을 정하며 쉽게 개발/배포/운영/유지보수할 수 있도록 하는 것이 아키텍처라 할 수 있다.
이런 아키텍처의 목표는 시스템을 만들고 유지보수하는데 투입되는 비용과 인력을 최소화함에 있다. 즉, 좋은 아키텍처를 만들면 시스템 수정하는데 비용이 적게든다는 것이며, 이는 곧 유지보수에 투입되는 비용과 인력을 적게 할 수 있는 이점이 있다.
로버트 C.마틴은 여러 아키텍처를 하나로 통합을 시도했다. 여기서 여러 아키텍처의 종류로 ‘헥사고날 아키텍처’, ‘BCE (Boundary-Control-Entity)’, ‘DCI (Data, Context and Interaction’ 가 있다.
이들의 공통 목표는 1) 관심사의 분리에 있으며, 이 목표를 이루기 위해서 2) 의존성 방향은 고수준의 안쪽을 향하도록 하는 핵심 규칙을 가진다. 즉, 모든 소스코드의 의존성은 반드시 외부에서 내부의 고수준 정책으로 향해야 한다. 업무 로직과 같은 고수준의 정책은 DB 종류나 활용 방식, UI 등과 같은 저수준의 정책 변경에 영향을 받지 않도록 세부 사항의 변경에 영향을 받지 않도록 해야 소프트웨어를 유연(Soft) 하게 유지시킬 수 있다.
아키텍처의 종류와 구조
클린 아키텍처 이전의 아키텍처로 ‘계층형’ 아키텍처가 존재한다.
1) 계층형 아키텍처
보통 웹 계층, 도메인 계층, 영속성 계층으로 3계층 혹은 4계층으로 이루어진 전통적인 구조이다. 구조가 단순하여 처음 시작할 때 적합하지만, 소프트웨어가 커짐에 따라 복잡해져 조직화에 도움이 되지 않고, 업무 도메인에 대해 아무것도 설명해주지 않는다는 단점 (→ 비즈니스 계층이 어떤 프레젠테이션 레이어에서 사용되있는 있는지 그 의존성을 알아내기가 어렵다) 이 존재한다.
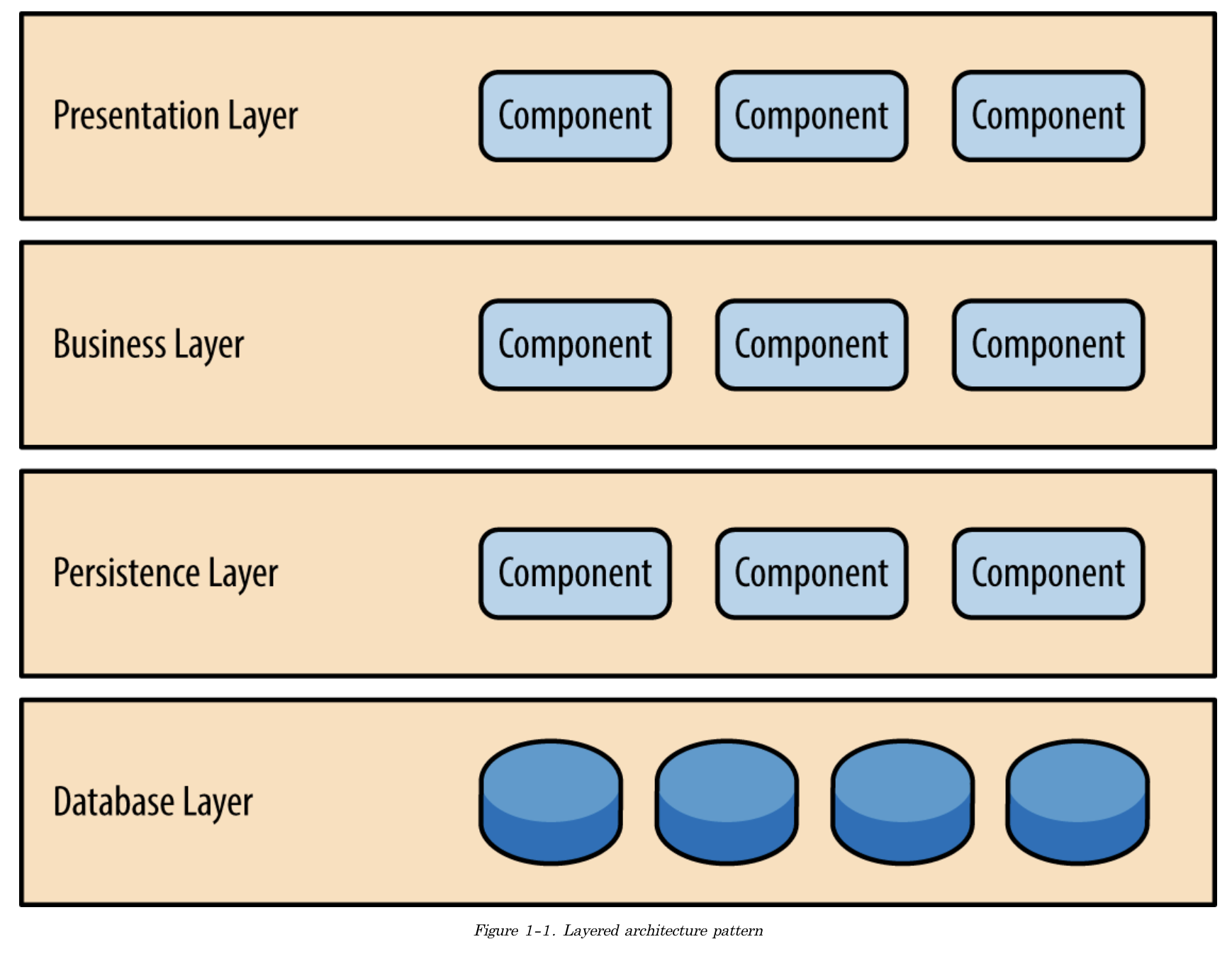
- Presentation Layer(or Controller / Web 계층): 유저 인터페이스, 브라우저 커뮤니케이션 로직을 다룬다. 사용자의 요청을 받아 도메인 계층에 있는 서비스로 요청을 보낸다.
- Buisiness Layer (or Domain, Service 계층): 특정 요청에 대한 주요 로직을 수행하고, 도메인 엔터티의 현재 상태를 조회하거나 변경하기 위해 영속성 계층의 컴포넌트를 호출한다.
- 엔터티: 데이터의 집합, 저장되고 관리되어야 하는 데이터
- Persistence Layer (or Data Access, 영속성 계층): 엔터티를 영구 저장하는 환경
계층형 아키텍처는 단방향 의존성을 가진다. 각각의 레이어는 자기보다 하위의 레이어에만 의존한다. 즉, 의존성의 끝이 결국 영속성 계층을 향하기 때문에 비즈니스 관점에서는 비즈니스 로직을 최우선으로 생각해야 하지만, 계층형의 특성상 도메인 최우선으로 두기가 쉽지 않다.
2) 클린 아키텍처
영속성을 향하는 단방향 구조의 계층형 아키텍처에 비해, 클린 아키텍처는 도메인 중심이다. 또한, 모든 의존성은 외부에서 내부로, 고수준 정책을 향하는 형식을 취한다. 규칙이 단순하고, 도메인이 세부 사항에 의존하지 않는 장점이 있지만, 패키지 구조가 계층형보다 복잡하고 레퍼런스가 적은 단점이 있다. 아래 사진은 클린 아키텍처의 구조를 재구성한 모습이다. NHN 포스팅에서 더 자세한 내용을 확인할 수 있다.
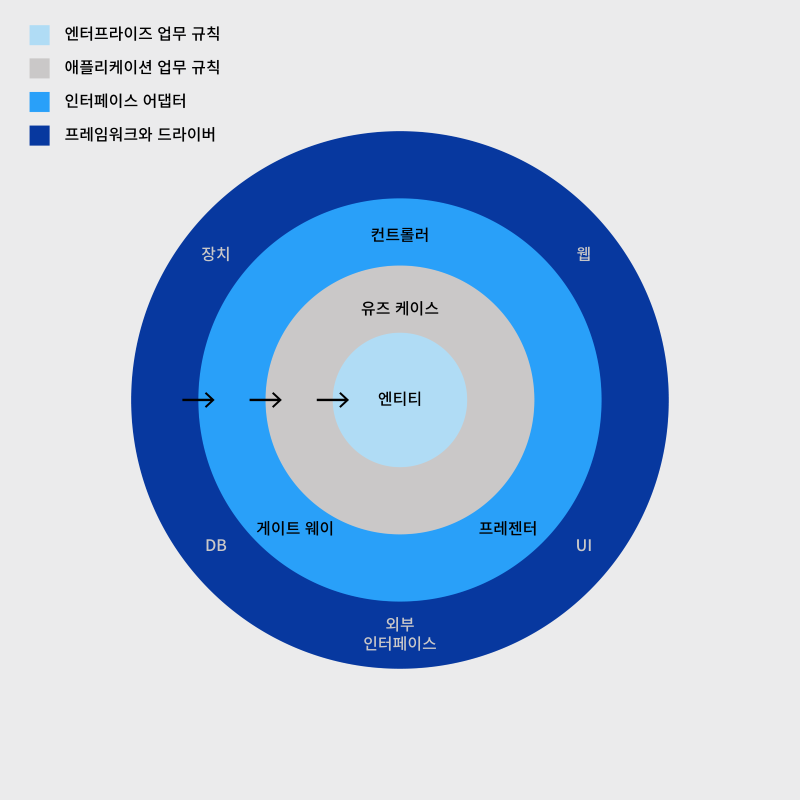
출처) https://meetup.nhncloud.com/posts/345
여기서 화살표 방향은 의존성을 의미한다. 클린 아키텍처의 의존성은 [밖 → 안]으로 향하며, 바깥 원은 안쪽 원에 영향을 미치지 않는다. 즉, 바깥으로 갈 수록 덜 중요하고 세부적인 영역으로 표현되며, 안으로 갈 수록 추상화된 개념으로 표현된다. 클린 아키텍처의 주요 구성을 안 쪽부터 설명하면 다음과 같다.
- 엔터티: 엔터프라이즈 업무 규칙 (Enterprise Business Rules)
- 핵심 업무 규칙을 캡슐화한다.
- 메소드를 가지는 객체, 일련의 데이터 구조와 함수의 집합
- 가장 변하지 않으며 외부로부터 영향을 받지 않는 영역
- 유즈 케이스: 애플리케이션 업무 규칙 (Application Buisiness Rules)
- 어플리케이션의 실제 비즈니스 로직을 포함한다.
- 엔티티로 들어오고 나가는 데이터 흐름을 조정하고 가공한다.
- 인터페이스 어댑터 (Interface Adapters)
- 일련의 어댑터들로 구성한다.
- 외부 인터페이스로 들어오는 데이터를 유즈 케이스와 엔티티에서 처리하기 편한 방식으로 변환하고, 유즈 케이스와 엔티티에서 나가는 데이터를 외부 인터페이스에서 처리하기 편한 방식으로 변환한다.
- 컨트롤러, 게이트웨이, 프레젠터가 존재한다.
- Frameworks & Drivers
- 시스템의 핵심 업무와는 관련 없는 세부 사항
- External Interfaces, DB, Devices, UI, Web 가 존잰한다.
이와 같은 클린 아키텍처에서 사용하는 의존성 규칙은 의존성 역전과 포트-어댑터를 이용하여 달성이 된다.
1) 의존성 역전
먼저 의존성 역전이란, 객체는 저수준의 모듈(구체적인 구현 객체)보다 고수준(인터페이스와 같은 추상적 개념)의 모듈에 의존해야 한다는 의미이다. 이해하기가 어려워, 간단한 예제 를 통해 확인을 해보려 한다. 예를 들어, 캐릭터가 무기를 갖출 수 있는 게임을 만든다고 생각해보자. 그럼 ‘캐릭터’와 ‘무기’라는 객체를 생성할 수 있을 것이다. 다양한 ‘무기’의 종류 중 ‘한손검(OneHandSword)’ 이라는 무기 객체를 구현했을 때, 캐릭터는 weapon 이라는 OneHandSword 를 참조하는 값을 입력값으로 받아 초기화를 진행한다고 가정한다.
1
2
3
4
5
6
7
8
9
class Character {
final String NAME;
int health;
OneHandSword weapon;
{...}
}
출처: https://inpa.tistory.com/entry/OOP-💠-아주-쉽게-이해하는-DIP-의존-역전-원칙 [Inpa Dev 👨💻:티스토리]
이때 캐릭터는 ‘한손검’ 뿐만 아니라, ‘양손검’ 같은 다양한 무기를 사용할 수 있을 것이다. 하지만, 현재 저수준의 객체인 OneHandSword 에 의존하고 있기 때문에, 캐릭터는 다양한 무기를 사용할 수 없게 된다. 그 이유는 캐릭터가 구체화된 하위 모듈(저수준 정책)에 의존하고 있기 때문이다. 만약 의존성 역전 규칙을 잘 지켰다면 고수준의 정책인 Weaponable 인터페이스(양손검 + 한손검 등등을 포괄) 를 새롭게 생성하여 의존함으로써, 더 다양한 무기를 사용할 수 있도록 할 수 있을 것이다. 정리하자면, 의존성 역전 규칙은 상위 계층이 하위 계층에 의존하는 전통적인 의존 관계를 ‘역전’ 시킴으로써, 상위 계층이 하위 계층의 구현으로부터 독립되게 하는 방식이다.
2) 포트-어댑터 패턴
포트-어댑터는 간단히 우리가 사용하는 ‘포트’와 ‘플러그인’ 을 생각해보면 된다. 포트는 장치를 연결하기 위한 규격과 같다. 포트의 목적이 다르면 모양 또한 달라진다. 어댑터는 규격이 다른 두 장치를 연결하여 작동할 수 있게 하는 결합도구인 플러그인과 같다. 이를 소프트웨어 분야에 적용하면 포트는 인터페이스이며, 도메인 밖의 데이터와 상호작용할 수 있는 역할을 수행한다. 어댑터는 인터페이스를 다른 인터페이스로 바꿔주는 클래스와 같다.
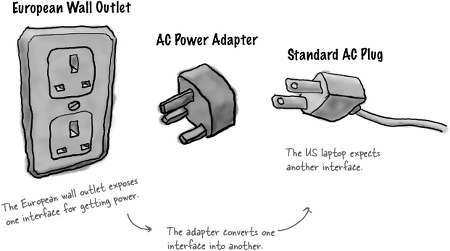
출처) Head first design patterns
위 사진에서 European Wall Outlet 은 110v 의 규격을 가진 Client 이며, 어댑터인 AC Power Adapter 가 220v 의 규격을 가진 외부 요소인 Standard AC Plug 와 연결함으로써 서로 규격을 동일하게 맞춰주고 있다. 서로 호환성이 없는 인터페이스와 클래스들을 연결시켜 동작할 수 있도록 도와주는 패턴이 어댑터 패턴이다.
이제 여기서 나아가, Hexagonal Architecture 에서 적용된 개념이 포트&어댑터 패턴이다.
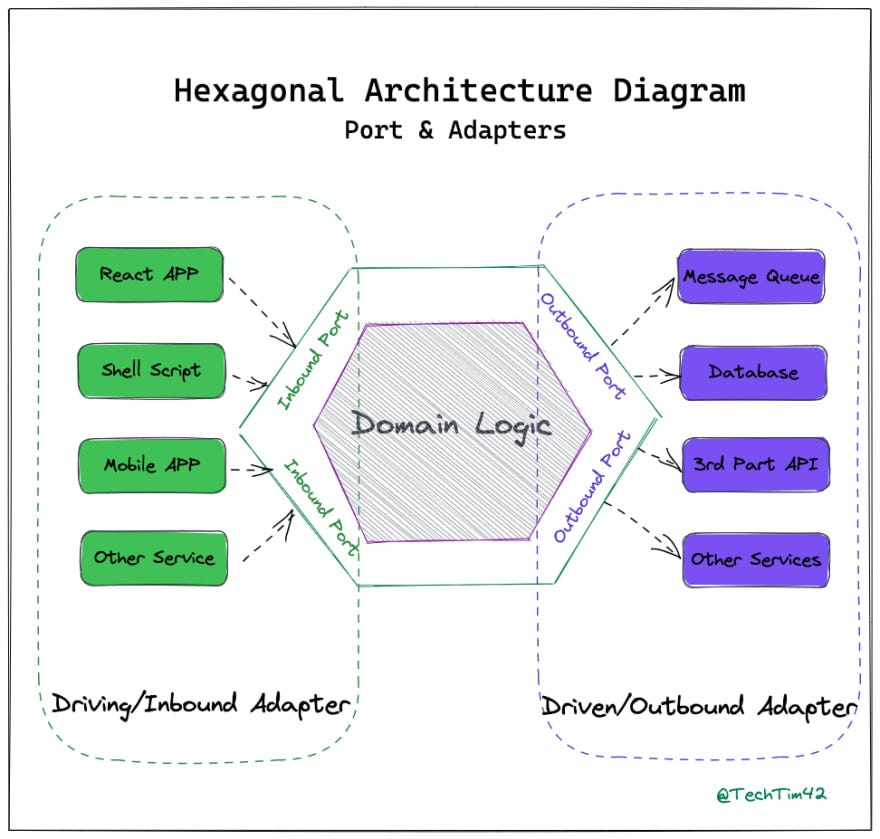
출처) https://medium.com/@TechTim42/learn-to-build-a-hexagonal-architecture-micro-service-11146955b57c
포트는 InBound(or InGoing, Driving)와 outBound(or OutGoing, Driven) 가 존재한다. InBound Port 는 내부 영역의 도메인 로직 사용을 위해 노출된 인터페이스이며, OutBound Port 는 도메인 외부 작업을 호출하는 인터페이스이다. 예를 들어, 외부 DB 의 CRUD 를 수행하거나 외부 API 를 호출하는 등의 작업에서 활용된다.
어댑터도 InBound(or Drving, Primary) 와 OutBound(or Driven, Secondary) 가 존재한다. InBound Adapater 는 외부 애플리케이션과 내부 비즈니스 영역(인바운드 포트) 간의 데이터 교환을 조정한다. OutBound Adapter 는 내부 비즈니스 영역(아웃 바운드 포트)과 외부 애플리케이션 간의 데이터 교환을 조정한다.
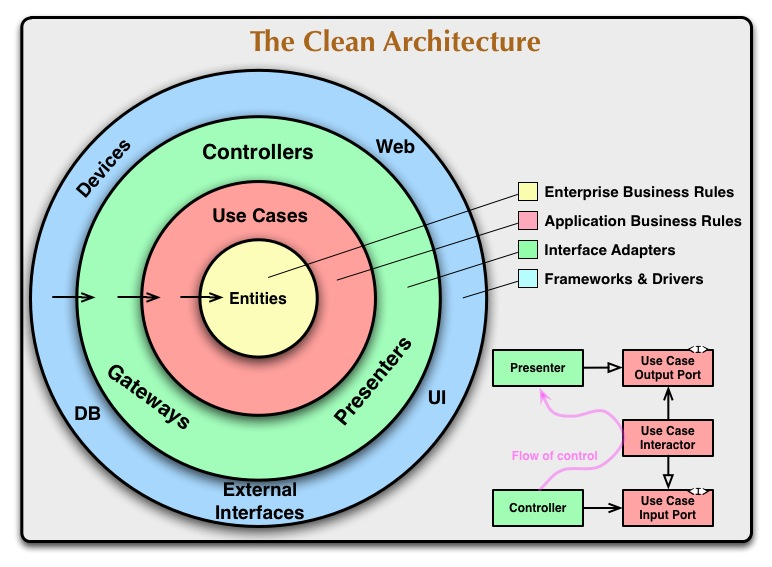
잠깐 위 아키텍처 구조에서 우측에 위치한
[1] Controller 에서 유저 이벤트를 처리한다. 이를 위해 Use Case Input Port 인터페이스를 구현한 객체의 메소드를 호출한다.
- 이때 Presentation 레이어(Interface Adapter) 와 Use Case 의 레이어(Application Buisiness Rules) 의 경계를 넘게 된다.
[2] Use Case Interactor (Use Case 의 구현)는 엔터티 또는 다른 도메인의 핵심 객체를 조정하여 전달된 요청을 처리한다.
[3] Use Case Interactor은 처리 결과를 받아서 Use Case Output Port 인터페이스를 구현한 객체의 메소드를 호출한다.
[4] Presenter 는 Use Case Interactor 로부터 결과를 받아서 (Presenter 가 구현하는 Use Case Output Port 인터페이스를 통해 전달), 적절한 형태로 변형하여 View Layer 에 전달한다.
- 참고하면 좋을 예제 https://justwrite99.medium.com/clean-architecture-part-2-the-clean-architecture-3e2666cdce83>
이런 포트-어댑터 패턴을 적용하면, 엔터티와 유즈 케이스 영역은 외부 요소가 어떤 기술로 정의되어있는지, 그 내부 동작을 알 필요가 없어진다. 즉, 외부 기능 변화에 오염되지 않고 의존성의 방향이 밖(어댑터 영역) → 안 (유즈케이스 영역) 으로 향할 수 있도록 하여 클린 아키택처의 의존성 규칙을 만족할 수 있게 된다. 실제 포트-어댑터가 어떤 식으로 의존성 규칙을 보조하는지에 대해서는 이 포스팅의 내용을 참고하면 된다.
예제
수많은 참고 코드가 있으나, 주로 Java 코드로만 이루어져 있어서 코드 이해조차 쉽지가 않았다. 그래서 리액트로 클린 아키텍처를 구현한 해당 예제를 참고했다. 🙇♀️ 아래는 예제 코드를 해석하면서 필요했던 사전 지식들이다.
- 모노레포 관련
- 하위 워크스페이스의 package.json 에 존재하는 script 를 실행하려면
yarn workspace [하위 package-name] [하위 package 의 script-name]
- 하위 워크스페이스의 package.json 에 존재하는 script 를 실행하려면
Folder Structure
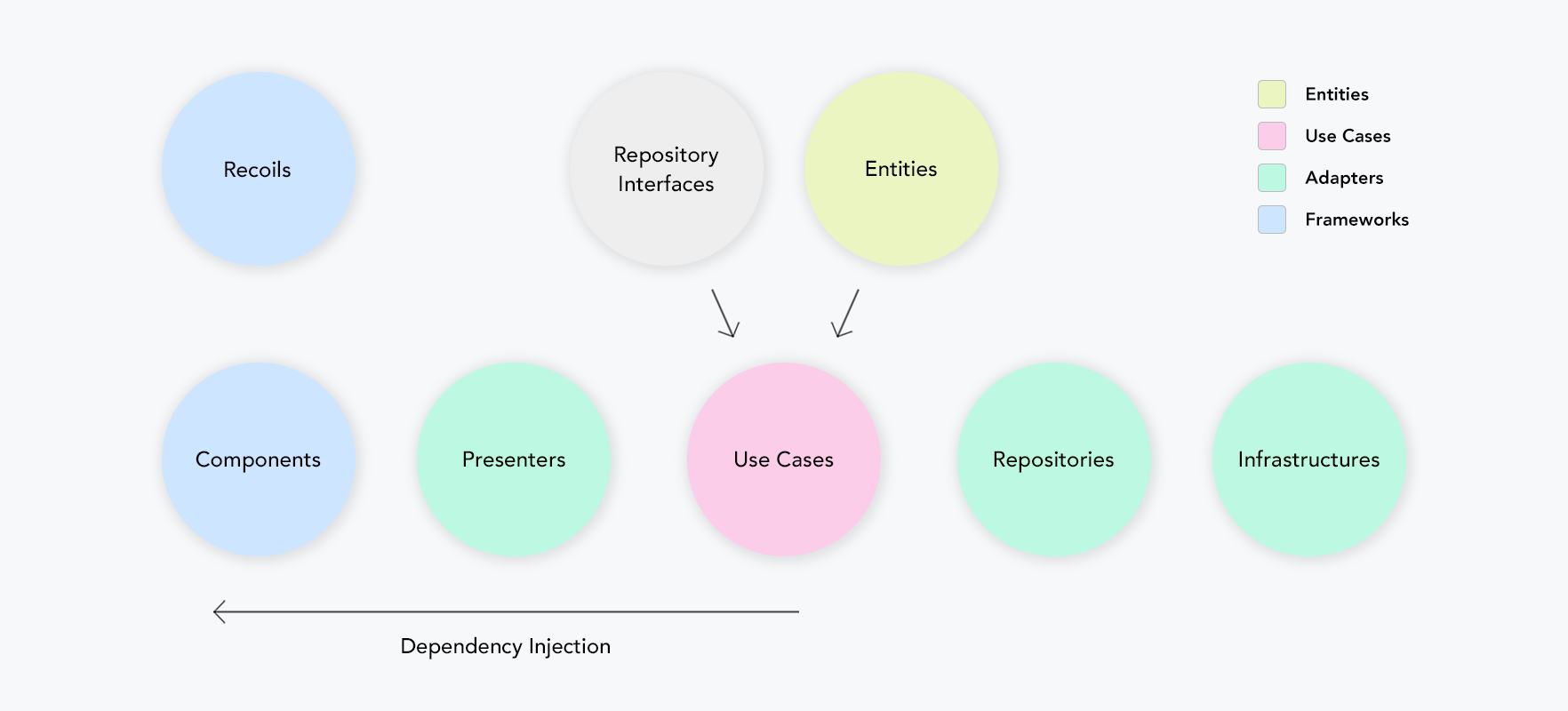
출처: https://github.com/falsy/react-with-clean-architecture
- domain
- entities
- 데이터베이스 테이블에 매핑되는 영구적인 데이터 구조 혹은 객체, 도메인 모델의 개념
Comment: 코멘트 정보 (id, author, content …)
- aggregates
- 각각의 도메인 영역을 대표하는 객체를 Aggregate(집합)라고 한다. Aggregate 를 활용하면 각각의 도메인에 Repository 로 묶어야 하는 Entity(객체)가 명확해진다.
Board(게시글): Comment 에터티를 이용하여 Board 정보에 comments 필드와 pushComment 메소드를 확장함.
- dto
- DTO(Data Transfer Object), 필요한 데이터 전송을 위한 객체
BoardDTO: Board 데이터 전송 객체CommentDTO: Comment 데이터 전송 객체UserDTO: User 데이터 전송 객체
useCases
출처) https://github.com/falsy/react-with-clean-architecture
- 사용자의 요청에 알맞게 상위 계층 엔터티 등을 가공, 출력 (DTO, Entity, Aggregates 활용)
- Use Case 는 Entity 를 사용할 수 있지만, Entity 는 Use Case 를 사용할 수 없다.
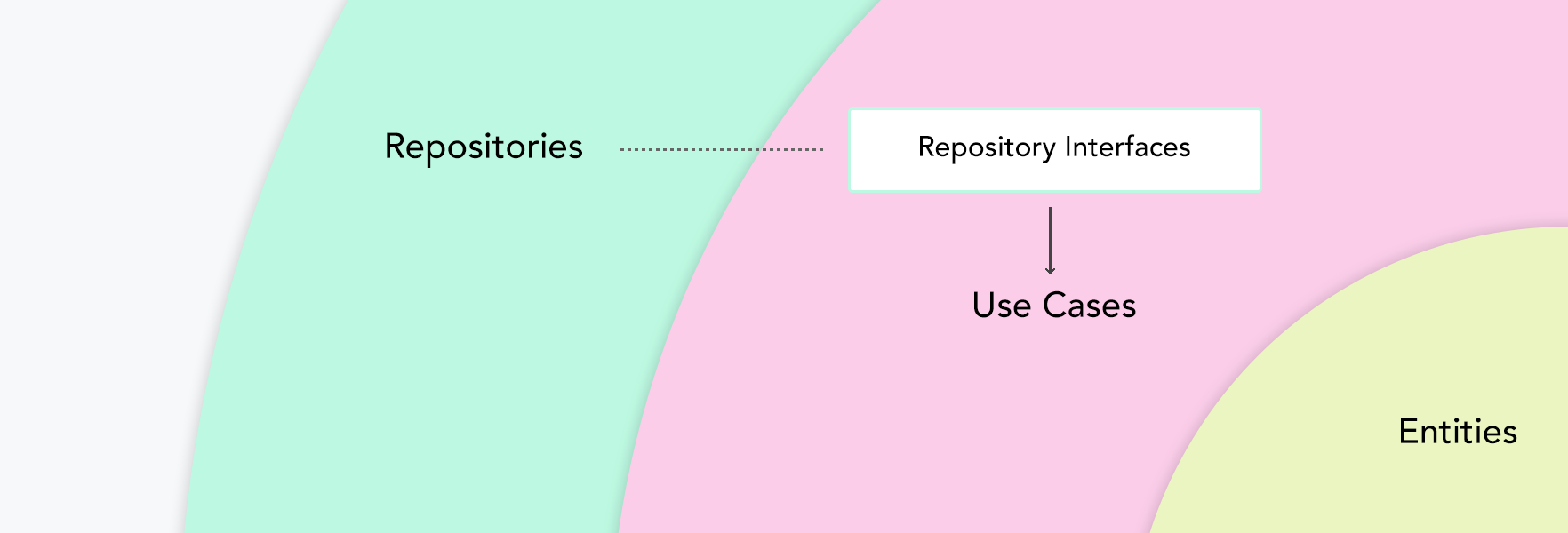
repository-interfaces: Use Case 는 Repository 정보에 대해 알면 안 되기 때문에, Domain 레이어(Entity + Use Case) 에서 Repository Interface 를 가지고 구현한다.IBoardRepository: getBoards, getComments, insertBoardISessionRepository: login, getToken, setTotken, removeToken
Board:IBoardRepository를 이용하여 유즈 케이스를 작성Session:ISessionRepository를 이용하여 유즈 케이스를 작성- 추후 Presenter 영역에서 useCases 에서 정의한 인터페이스를 활용하여 데이터에 접근함
- entities
- adapter
- domain 과 infrastructure 사이의 번역기 역할을 수행한다. presenters, repositories 에 해당한다.
- infrastructure
- 컨트롤러, 게이트웨이, 프레젠터 (데이터 형식을 변환하는 역할 수행)
Http: Http 객체의 request 메소드 호출을 통해 fetch json 응답값을 반환Storage: Storage 객체의 remove, get, set 메소드를 통해 localStorage 의 값을 관리
- repositories
- infrastructure 의 http 와 storage 를 활용하여 DB api 를 호출하거나, 그 응답을 조합하여 DTO 객체를 리턴
Board: getBoards, getComments, insertBoardSession: login, getToken, setToken, removeToken
- presenters
- UI 로부터 input data 를 받아 Use cases와 Entites 에게 편리한 형태로 가공 or Use cases와 Entities 의 ouput 을 가져와 UI 에 표시하거나 DB 에 저장하기 편리한 형식으로 가공
Board: useCases 에 정의된 getBoards, insertBoard 리턴Session: useCases 에 정읜된 login, getToken, setToken, removeToken 리턴
- di (dependency injection)
infrastructure: adapter 에서 정의한 infrastructure 를 이용하여 객체 생성presenter: adapter 에서 정의한 presenter 를 이용하여 객체 생성repositories: adapter 에서 정의한 repositories 를 이용하여 객체 생성useCases: domain 에서 정의한 useCases 를 이용하여 객체 생성
1 2 3 4 5 6 7 8 9 10 11 12 13 14
// di const cInfrastructures = infrastructures(); // infrastructure 를 이용하여 session 과 board 생성 const cRepositories = repositories(cInfrastructures); // repository의 session 과 board를 이용하여 useCase 를 생성 const cUseCases = useCases(cRepositories); // useCase 의 session 과 board 를 이용하여 presenter 를 생성 const cPresenters = presenters(cUseCases); // presenter 의 board 와 session 을 UI 에서 사용 export default { board: cPresenters.board, session: cPresenters.session, };
- 참고자료
- domain